Warren D. Smith June 2011
We'll first review what the shortest splitline algorithm is, then explain how to use fancy algorithms techniques from computational geometry, to program it so it is guaranteed to run quickly (even on worst-case input) and with high accuracy (in fact exact if we had exact real arithmetic and knew the exact country-shape and people locations).
This page is intended for perfectionists. Even fairly crude algorithmic approaches suffice to deliver acceptable accuracy in acceptable time on realistic input, so the methods discussed here are not really necessary.
Was invented by Warren D. Smith in the early 2000s. It is a very simple mechanical procedure that inputs the shape of a country and the locations of its inhabitants, and a positive number N, and outputs a unique subdivision of that country into N equipopulous districts.
Formal recursive formulation of shortest splitline districting algorithm:
ShortestSplitLine( State, N ){
If N=1 then output entire state as the district;
A = floor(N/2);
B = ceiling(N/2);
find shortest splitline resulting in A:B population ratio
(breaking ties, if any, as described in notes);
Use it to split the state into the two HemiStates SA and SB;
ShortestSplitLine( SB, B );
ShortestSplitLine( SA, A );
}
Notes:
Example: The picture shows Louisiana districted using the shortest splitline algorithm using year-2000 census data.
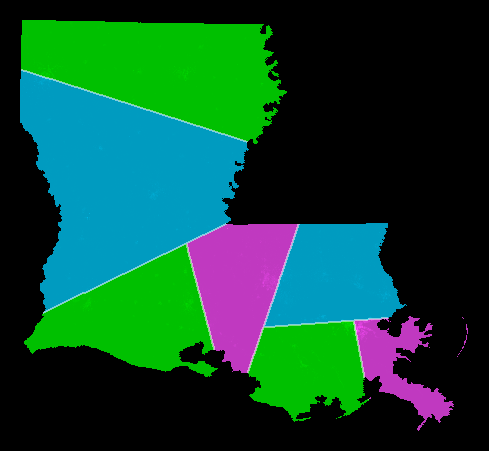
Want N=7 districts. Split at top level: 7 = 4+3. This is the NNE-directed splitline. Split at 2nd level: 7 = (2+2) + (1+2). Split at 3rd level: 7 = ((1+1) + (1+1)) + ((1) + (1+1)). result: 7 districts, all exactly equipopulous.
Theorem (single split-stage of SSA): Given as input:
A randomized algorithm exists (on a pointer machine with real arithmetic) to find the (exact) "shortest splitline" which splits the population in any specified ratio, in
steps, while consuming O(P+V) memory cells. Here α(x) is an inverse Ackermann function (extremely slowly-growing) while h(P) is the largest possible number of halving lines for a P-point set in the plane. Tamal Dey proved that h(P)≤25/3P4/3, which was improved to by Khovanova & Yang 2012 to h(P)≤[(40/3)(P-1)P3]1/3 (which reduces the constant factor to 74.7% of Dey's value). A conjecture of Erdös et al says h(P)=P1+o(1). In the other direction, point sets constructed by Geza Toth show h(P)≥Pexp((lnP)1/2C) for some constant C>0. [G.Toth: Point sets with many k-sets, Discrete & Computational Geometry 26,2 (2001) 187-194.] Thus given Erdös's conjecture our runtime bound is
steps.
Corollary (full SSA): Given also an integer N with 2≤N≤P, we can run the whole shortest splitline algorithm to subdivide the country into N equipopulous (to within 1 person) districts, in
steps while consuming O(P+V+N) memory cells. Given Erdös's conjecture this runtime bound is
Conjectural Further Speedup: If the country is specified using only a single simple polygon (now no polygonal "holes" nor multiple connected components are allowed; the word "simple" means "not self-crossing") then the "logV" in all the runtime bounds above, can be omitted (i.e. replaced by "1"). If we do allow holes and multiple components then still it ought to be possible to attain
Optimality: These algorithm runtimes and space-usages obviously are optimal to within logarithmic and inverse-Ackermanic factors and a factor of h(P)/P. All of these are slow growing. If this full scheme is programmed it should be extremely fast and accurate, perhaps running in only a few minutes for an entire country using IEEE double precision real arithmetic to find the exact splitline to 9 decimal places, i.e. centimeter accuracy.
Proof (how the algorithm works): We simply combine a lot of known algorithmic results from computational geometry.
Notes on the conjectural further speedup: A V-vertex simple polygon can be triangulated in O(V), not VlogV time using an extremely complicated algorithm by Chazelle 1991 (see also Amato, Goodrich, Ramos 2000). The GHLST data structure then can be built in O(V), not VlogV, time for a simple polygon. The convex hull of a single simple polygon can be found in O(V), not VlogV time using a method related to the "Graham scan."
The Voronoi diagram of the vertices of a convex V-vertex polygon can be built in O(V), not VlogV time using a method of Aggarwal & Shor 1987. (This is relevant to the final step of our algorithm involving convex subchains SA and SB of the polygonal boundary.) This suggests that the distance between two convex polygonal chains, with V vertices in all, both inward-bending, should be computable in O(V) not VlogV time. (That was already known using 2D convex-programming methods if they both are outward-bending and with disjoint convex hulls.) I suspect by some "moving fingers" methods the need for the GHLST data structure can be eliminated and so can the need for the binary-search-like procedure on the convex hull, but we nevertheless could obtain O(1) query-time in an "amortized" sense.
Notes for practical programmers (as opposed to algorithm-theoreticians who want theoretical guarantees): In practice I would recommend a number of shortcuts to make programming simpler without costing much:
A. Aggarwal, L. Guibas, J. Saxe, P. Shor: A Linear time algorithm for computing the Voronoi diagram of a convex polygon, Discrete & Computational Geometry 4 (1989) 591-604. See also L.Paul Chew: Building Voronoi Diagrams for Convex Polygons in Linear Expected Time, (1990) Dartmouth Dept. of Math & Computer Science PCS-TR90-147.
Nancy M. Amato, Michael T. Goodrich, Edgar A. Ramos: Linear-Time Triangulation of a Simple Polygon Made Easier Via Randomization, In Proc. 16th Annu. ACM Sympos. Comput. Geom SoCG (2000) 12pp
Jean-Daniel Boissonnat, Olivier Devillers, Rene Schott, Monique Teillaud, Mariette Yvinec: Applications of Random Sampling to on-line algorithms in computational geometry, Discrete & Computational Geometry 8,1 (1992) 51-71.
Timothy M. Chan: Remarks on k-level algorithms in the plane (1999).
Bernard Chazelle: Triangulating a simple polygon in linear time, Discrete & Computational Geometry 6 (1991) 485-524.
Steven J. Fortune: A sweepline algorithm for Voronoi Diagrams, Algorithmica 2,2 (1987) 153-174.
A.Fournier & D.Y.Montuno: Triangulating simple polygons and similar problems, ACM Trans.Graphics 3,2 (1984) 153-174. [O(NlogN) algorithm and O(N) if begin from a "trapezoidation."]
Leonidas Guibas, John Hershberger, Daniel Leven, Micha Sharir, Robert E. Tarjan: Linear-time algorithms for visibility and shortest path problems inside triangulated simple polygons, Algorithmica 2,1-4 (1987) 209-233.
Sariel Har-Peled: Taking a walk in a planar arrangement, SIAM J. Comput., 30,4 (2000) 1341-1367.
D.G.Kirkpatrick: Optimal Search in Planar Subdivisions, SIAM J.Computing 12,1 (1983) 28-35.
Nimrod Megiddo: Linear-Time Algorithms for Linear Programming in R3 and Related Problems, SIAM Journal on Computing 12,4 (1983) 759-776.
Neil Sarnak & R.E. Tarjan: Planar Point Location Using Persistent Search Trees, Communications of the ACM 29,7 (1986) 669-679.
"Soft-surfer" guide to O(NlogN)-time algorithms to compute convex hull of N points in plane.
Emo Welzl: Smallest Enclosing Disks (Balls and Ellipsoids), pp.359-370 in H. Maurer (Ed.), New Results and New Trends in Computer Science, Springer Lecture Notes in Computer Science #555, (1991). See also Bernd Gärtner: Fast and Robust Smallest Enclosing Balls, Proc. 7th Annual European Symposium on Algorithms (ESA), Springer Lecture Notes in Computer Science #1643, pp.325-338.
Chee K. Yap: An O(n log n) Algorithm for the Voronoi Diagram of a Set of Simple Curve Segments, Discrete & Comput. Geometry 2,4 (1987) 365-393.